Why Timetabling Needs a Solver
A university week is a grid of time slots, and every teacher, room, and student group is a resource that can only be in one place at once. Placing dozens of lectures, TDs, and TPs without a single clash is a constraint-satisfaction problem that grows combinatorially—doing it by hand guarantees mistakes.
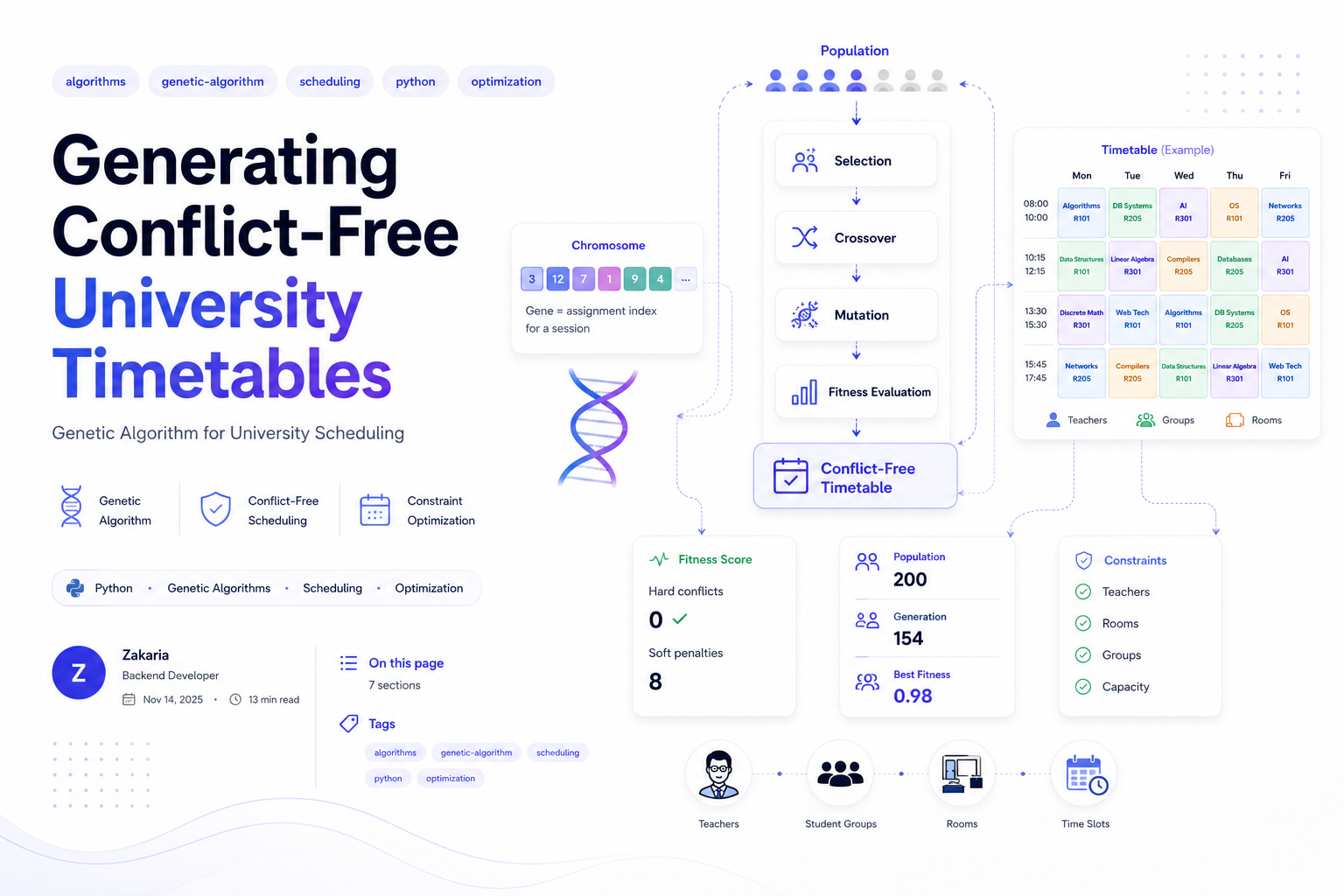
The HSupp backend already detects conflicts when a seance is written. But detection only tells you a schedule is broken. To generate a working schedule from scratch, HSupp ships a standalone Python genetic algorithm that searches the space of assignments for a conflict-free, well-balanced timetable.
Chromosome Encoding
Each required session (a SessionTemplate) is one gene. Rather than storing raw (slot, room, teacher) tuples, the problem precomputes a list of feasible assignments per template—only the combinations where the teacher is authorized for the subject and the room can host the session. A gene is just an index into that list, which keeps crossover and mutation trivially valid.
A chromosome is the full list of genes: one assignment choice for every session that must be scheduled.
@dataclass
class Gene:
template_index: int
assignment_index: int # -1 means unscheduled
@dataclass
class Chromosome:
genes: List[Gene]
fitness: Optional[float] = NoneHard vs Soft Constraints
Fitness is a cost to minimize. Hard-constraint violations—teacher, room, or group double-bookings, unauthorized teachers, TD scheduled before its lecture, or insufficient total seats—each add a penalty of 1000. Soft preferences—gaps in a day, too many consecutive teaching days, room-type mismatches, cross-department room usage, and uneven teacher workload—add small penalties.
Collapsing everything into one scalar cost lets the GA trade off cleanly: a schedule with zero hard violations always beats one with even a single clash, but among feasible schedules the algorithm still prefers tight, balanced ones.
- HARD = 1000.0 — double bookings, unauthorized teacher, ordering, capacity
- SOFT = 1.0 — gaps, consecutive-day streaks, room-type and department mismatches
- Unscheduled sessions are penalized as hard violations to force full coverage
Detecting Clashes During Evaluation
For each gene the evaluator records which (resource, day) pairs are occupied and checks overlap against everything placed so far. A lecture is section-level, so it implicitly occupies every group in that section—exactly the same hierarchy subtlety the Mongoose conflict hook handles on the API side.
for existing in teacher_slots.get(t_key, []):
if self._slots_overlap(existing, slot):
hard_penalty += HARD
teacher_slots.setdefault(t_key, []).append(slot)
@staticmethod
def _slots_overlap(a: TimeSlot, b: TimeSlot) -> bool:
if a.day != b.day:
return False
return not (a.end_min <= b.start_min or b.end_min <= a.start_min)Seeding, Elitism, and Adaptive Mutation
The initial population is half random and half greedy: the greedy individuals walk the templates and pick the first assignment that does not clash with what is already placed, so the GA starts near feasibility instead of from noise.
Each generation keeps the top 10% (elitism), fills the rest via tournament selection and single-point crossover, and mutates. When the best fitness stops improving for 20 generations, the mutation rate doubles (capped at 0.3) to escape local optima, then a repair step tries to schedule any sessions left unassigned.
# Keep the top 10% unchanged
elite_count = max(2, self.config.population_size // 10)
for i in range(elite_count):
new_population.append(self._clone_chromosome(sorted_pop[i]))
# Ramp up mutation when stuck
mutation_rate = self.config.mutation_rate
if stagnation_count > 20:
mutation_rate = min(0.3, mutation_rate * 2)Decoupling the Optimizer
The scheduler is a pure-Python package with no database dependency—it consumes plain dicts shaped like the existing Mongo models (Teacher, Subject, Room, Section, Group). In production the Node backend would serialize those collections to JSON, hand them to the GA, and persist the returned assignments as seances, reusing the same conflict hook as a final guarantee.
Keeping optimization off the request path means the API stays responsive and the algorithm can be tuned and tested in isolation—the natural next step is exposing it behind a single scheduler endpoint.